웹페이지
웹페이지 문서는 URL을 입력해 해당 페이지와 하위 페이지를 자동 크롤링하고, 결과 중 원하는 페이지만 선택해 지식 베이스에 추가합니다. 회사 홈페이지, 도움말 센터, 제품 페이지처럼 웹에 공개된 정보를 에이전트가 바로 활용할 수 있도록 해줍니다.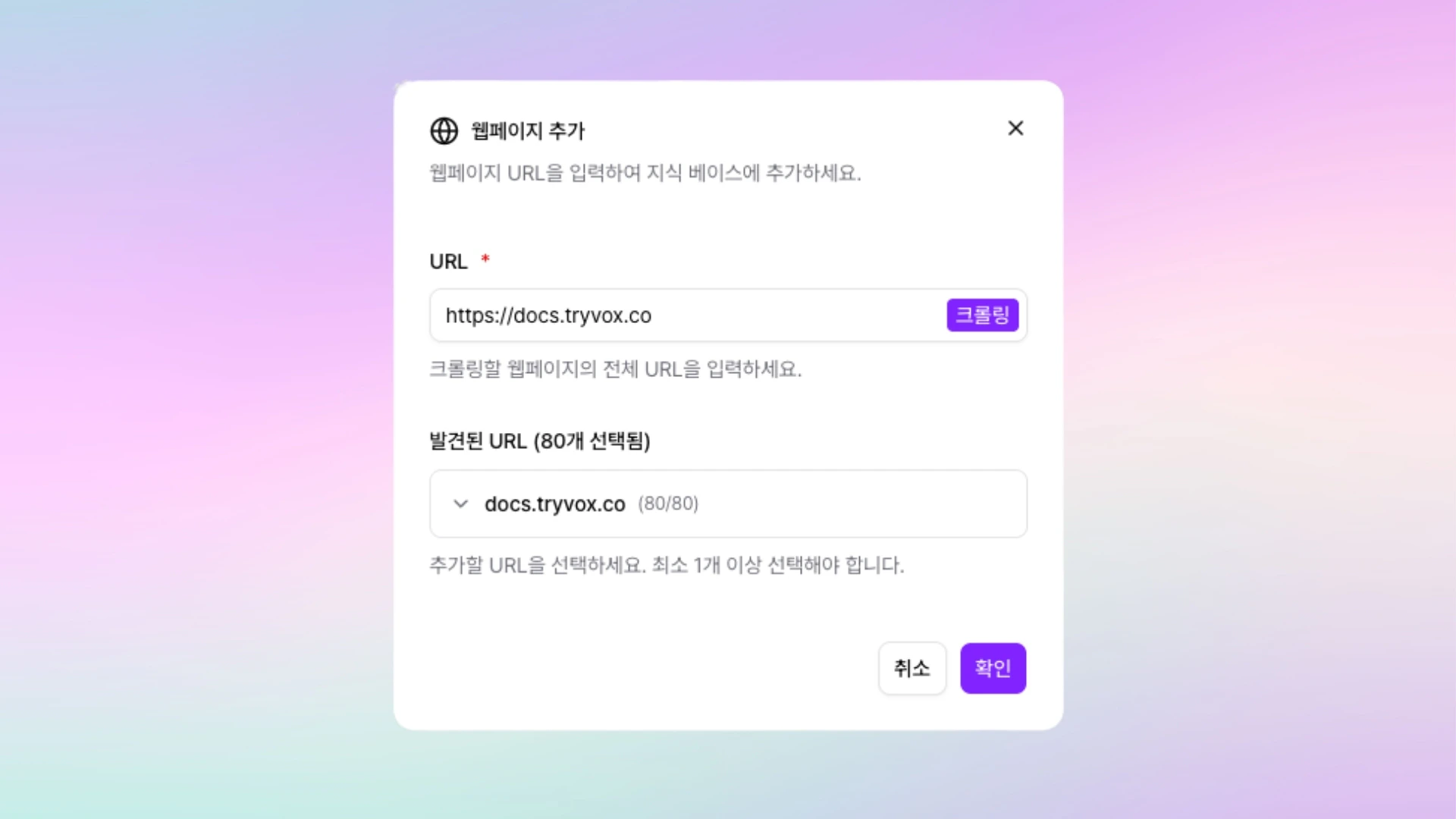
추가 방법
지식 베이스 상세 페이지의 추가 드롭다운에서 웹페이지를 선택하면 다이얼로그가 열립니다.URL
크롤링을 시작할 웹사이트의 전체 주소를 입력합니다. 입력란 옆에는 크롤링 버튼이 붙어 있습니다.- 플레이스홀더:
https://example.com https://까지 포함한 전체 URL을 입력해야 합니다. 잘못된 형식이면 “유효한 URL을 입력해주세요 (예: https://example.com)” 메시지가 표시됩니다.- 입력 후 Enter를 누르거나 크롤링 버튼을 눌러 크롤링을 시작합니다.
크롤링
크롤링 버튼을 누르면 입력한 URL을 시작점으로 서브도메인을 포함해 자동으로 탐색합니다. 도메인당 최대 100개까지 수집됩니다.발견된 URL
크롤링이 끝나면 수집된 URL이 도메인별로 그룹화되어 표시되고, 라벨에는 현재 선택된 URL 개수가발견된 URL (N개 선택됨) 형태로 나타납니다.
- 각 도메인 블록은 접고 펼 수 있으며, 도메인 이름 옆에는
(선택 수 / 전체 수)배지가 붙습니다. - 블록을 열면 상단에 모두 선택 체크박스가 있고, 그 아래로 개별 URL 체크박스가 이어집니다. 기본값으로 모든 URL이 선택되어 있습니다.
- 도메인당 처음에는 10개의 URL만 보이고, 그보다 많으면 +N개 더보기 버튼이 나타납니다. 확장 상태에서는 간략히 보기로 다시 접을 수 있습니다.
- 입력란 아래에는 “추가할 URL을 선택하세요. 최소 1개 이상 선택해야 합니다.” 라는 안내가 표시됩니다. 최소 1개 이상의 URL이 선택되어야 저장할 수 있습니다.
제약 사항
| 항목 | 값 |
|---|---|
| 도메인당 최대 크롤링 URL 수 | 100개 |
| 크롤링 범위 | 입력한 URL의 동일 도메인 및 서브도메인 |
| 접근 가능 페이지 | 공개 페이지만 (로그인이 필요한 페이지는 수집 불가) |
에러 처리
- URL 형식 오류: 입력창 아래에 즉시 오류 메시지가 표시되고, 같은 내용이 토스트로도 나타납니다.
- 크롤링 실패: 대상 서버가 응답하지 않거나 robots.txt로 차단된 경우 “URL 크롤링에 실패했습니다” 토스트가 표시됩니다. 브라우저에서 해당 URL이 정상 접근되는지 먼저 확인하세요.
- 콘텐츠 없음: 크롤링은 성공했지만 텍스트 콘텐츠가 없는 페이지(이미지뿐인 경우 등)는 유효한 정보가 추가되지 않을 수 있습니다.
크롤링 결과는 추가 시점의 스냅샷입니다. 원본 웹사이트가 업데이트되면 지식 베이스에서 해당 문서를 삭제하고 다시 추가해야 최신 내용이 반영됩니다.
관련 문서
연관 검색어
연관 검색어
웹페이지, webpage, 크롤링, crawling, URL, 자동 크롤링, 지식 베이스 웹